Gallalaus: An Expedition into Full Stack Development - System design
I'm Flavius Cojocariu, a friendly and experienced Software Engineer, based in München, Germany, with a keen focus on crafting amazing web experiences. I believe in embracing life's adventures and constantly seeking opportunities to grow and learn. Let's dive into my story!
My work philosophy revolves around constant growth and innovation. I believe that staying curious and adaptable is crucial in an ever-evolving landscape. Through each project, I aim to deliver not just results but also meaningful experiences that resonate with audiences and clients alike.
Throughout my career, I've been fortunate enough to contribute to some pretty fantastic projects. From responsive websites that adapt like chameleons to web applications with seamless user experiences, I take immense pride in every line of code I write. Some of the companies I have worked for are part of the IoT/fintech industry, travel industry, and even telecom and market research.
I'm excited about the future and the possibilities it holds. I'm open to new collaborations, challenges, and endeavors that push the boundaries of creativity and innovation.
Thank you for taking the time to explore my portfolio. If you have any questions, want to discuss potential projects, or simply want to connect, don't hesitate to reach out.
Embark on the next leg of our Full Stack Development expedition with this fourth post in the Gallalaus series! In this chapter, I'll discuss the importance of system design, how to identify the main components, and how to work toward a successful MVP release
What is System Design? Why is it important?
System design is the process where the architecture, modules, the components that compose those modules, as well as the interfaces that describe the components and the data models of the system, are defined based on a clear set of requirements. This process is really important at the beginning of the project, in order to understand clearly what and how it needs to be developed, iron out the status quo, and especially better define the priority in which the tasks should be developed. In a nutshell, this can be expressed like this: System Design is the art of creating a blueprint that satisfies the requirements and needs of users and stakeholders.
How to Identify Key Components?
As we know by now, the system design process is based on a clear set of requirements. Let's write down some requirements for what a bug tracker system should contain. Then we can analyze them and iron out the main components of the system, and draw the picture of how the communication layer should be and what our data model should look like.
Requirements:
Users can create a task/bug only attached to a list and part of a board.
Users can log in based on username/password or via an SSO mechanism.
Tasks/bugs can have the following properties:
Title
Description
Assignee
Author
Labels
Status
Priority
Created date
Updated date
Updated by (who updated the task details?)
Attachments
Users who can see the task can place comments on it.
Users who can see the task should be able to sign up for notifications regarding the task.
Lists can't be deleted if there are tasks.
Boards containing non-empty lists can't be deleted.
Users should be able to select multiple tasks in a list and delete/move them.
There should be at least 3 levels of user roles, system-defined:
Admin
Normal
Guest
Users should not have to refresh the page to get updates of boards/lists/tickets.
The system should always notify the creator and assignee via email if a ticket was updated.
Now that we have a good set of requirements, we can start clustering them into two main categories, with the mindset for MVP:
MVP Status Quo
Users can create tasks/bugs only attached to a list and part of a board.
Users can log in based on username/password.
Everyone can see everything and comment.
Lists can't be deleted if there are tasks.
Boards containing non-empty lists can't be deleted.
Should have 2 levels of user roles, system-defined:
Admin
Normal
Nice to Have
Users can log in via an SSO mechanism.
Users who can see the task can place comments on it and get notified (add view permission).
Users should be able to select multiple tasks in a list and delete/move them.
Guest user role.
Users should not have to refresh the page to get updates of boards/lists/tickets.
Email notification of the creator and assignee of a ticket.
Clustering the requirements into such lists offers us the possibility to be more focused on what should be included in the MVP and keep an eye on the future extensibility of the system. In the context of an MVP, the "Nice to Have" list contains features that are not crucial during the testing phase of the product.
We can now move on to the next section, where we can see how we take the status quo cluster and translate it into our main components of the system.
System Architecture Overview
Now that we have found our status quo list of requirements let's look at our components in the following UML component diagram.
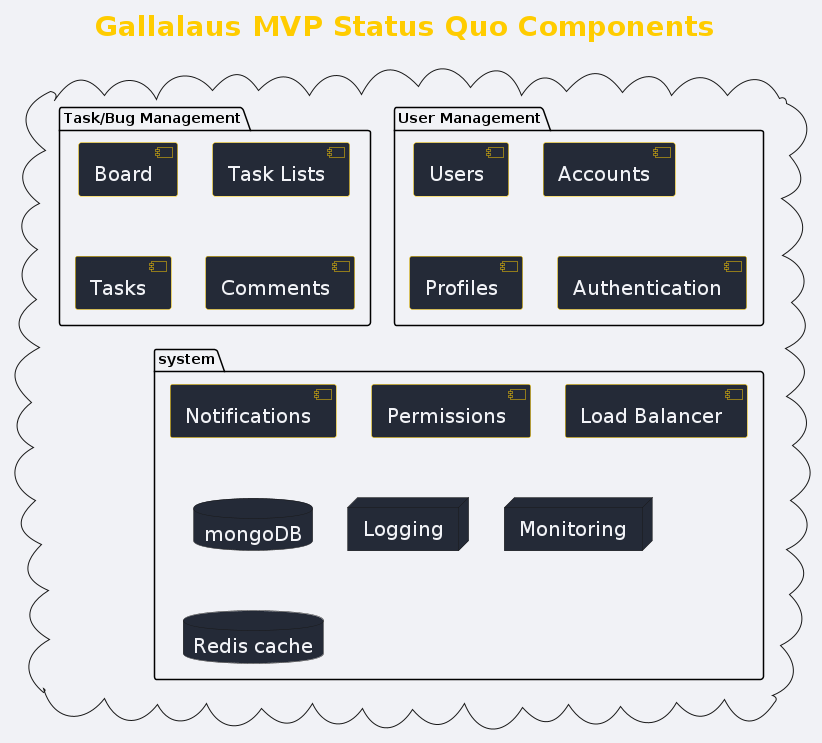
As we can notice in the diagram, we have three main component clusters, which can be named as preferred in the end; the names themselves don't matter at this stage. These modules contain our main key components derived from the status quo requirements list.
User Management Module
Within the User Management module, we have defined both 'Accounts' and 'Profile' components. Although there are no specific requirements listed for them, from a system perspective, these are two important components/features. 'Accounts' will enable us to manage user objects more effectively, while 'Profiles' will empower platform users to configure their specific platform settings. As both components are derived from the component specifications and are not part of the status quo, we can safely consider them as 'nice to have' for the MVP.
Task/Bug Management Module
This module contains the key components, that we found in the status quo list. To simplify and allow for the extensibility of the system, comments are treated as a standalone component and are not part of the task.
System Module
As part of the System module, we have found a number of components. For now part of the status quo we will only have:
Load Balancer
The load balancer component will be more of a reverse proxy for the moment.
Permissions
The permissions component will only help make a differentiation between admin and normal users for now.
MongoDB
For the MVP we will make use of mognoDB.
Caching
For caching, we will use Redis cache. For MVP purposes we will only store users session credentials, so we can keep them logged in even if we restart the server.
Logging
For monitoring the logging, we will store all application logs in a specific log file.
Other 'Nice to Have' Components
The rest of the System module components can be moved into the 'nice to have' list. Furthermore, we can add also the components that will be partially implemented during MVP in the same list.
Frontend-backend communication
For now, as we are focusing only on delivering the MVP first, the communication layer between frontend(FE) and backend(BE) services will be pure HTTP, based on the REST API provided by the backend services.
Here is an example of the ticket creation sequence diagram, to exemplify the communication layer between FE-BE.

As we can see in the above UML sequence diagram, the communication layer, for the MVP is quite simple. Let's not forget that the MVP's purpose is to release fast, with a clear status quo list, and provide usability to the users. A nice exercise is to create by your own the rest of the sequence diagrams, in order to get the exercise going, and make this a routine.
Database Design
For the MVP, our database design will be intentionally simple. As mentioned in the System Architecture Overview section, we'll be using MongoDB. It's worth noting that despite the data having some relational aspects, we've chosen MongoDB for its flexibility. During MVP development, this flexibility allows us to add missing fields on the fly and work with potentially inconsistent data. While inconsistent data is generally not ideal, it's acceptable for the MVP phase. It's important to remember that after completing the MVP and moving towards v1, we may consider changing the database technology entirely.
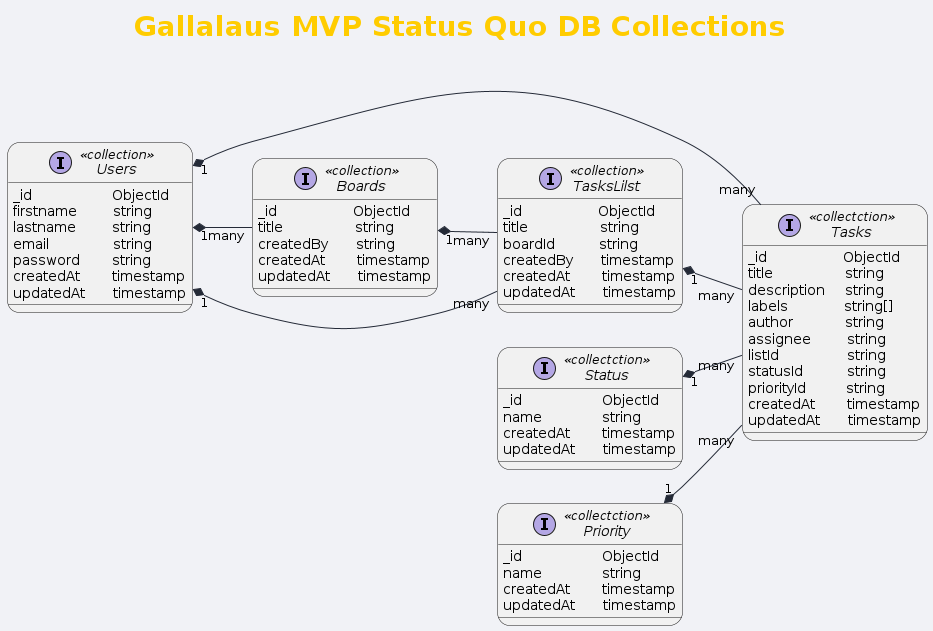
Based on the requirements list, we can see how the Tasks collection is structured. The other collections schemas, we could take from the fucntional requirements of the status quo list. From the db diagram, we can see that the relationships between the collection is mainly many to 1, where we have:
Many tasks to 1 user
Many tasks to 1 list
Many tasks to 1 status
Many tasks to 1 priority
Many lists to 1 user
Many lists to 1 board
Many boards to 1 user
Some remarks though for the Tasks collection, is that the author and assignee, both relate to the users collection, because 1 user could create the ticket/bug, but another one could work on it. The Users.roles will be a enum list, maintained in the code for the moment, as there would be not so much work on the permission side.
OpenAPI Specifications
What is OpenAPI?
The OpenAPI Specification is a specification language for HTTP APIs that provides a standardized means to define your API to others. You can quickly discover how an API works, configure infrastructure, generate client code, and create test cases for your APIs. For more details, you can find information here.
Why I Choose OpenAPI
I prefer using OpenAPI specifications because of its straightforward integration with NestJS. For our backend, I propose using this API specification for the tasks module.
openapi: 3.0.0
paths:
/tasks:
post:
operationId: TasksController_create
parameters: []
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/CreateTaskDto'
responses:
'201':
description: ''
tags:
- tasks
get:
operationId: TasksController_findAll
parameters:
- name: size
required: false
in: query
schema:
maximum: 1000
type: number
- name: page
required: false
in: query
schema:
type: number
responses:
'200':
description: ''
tags:
- tasks
/tasks/{id}:
get:
operationId: TasksController_findOne
parameters:
- name: id
required: true
in: path
schema:
type: string
responses:
'200':
description: ''
tags:
- tasks
patch:
operationId: TasksController_update
parameters:
- name: id
required: true
in: path
schema:
type: string
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/UpdateTaskDto'
responses:
'200':
description: ''
tags:
- tasks
delete:
operationId: TasksController_remove
parameters:
- name: id
required: true
in: path
schema:
type: string
responses:
'200':
description: ''
tags:
- tasks
info:
title: gallalaus API
description: The API specification for the gallalaus with address undefined
version: 0.0.1
contact: {}
tags: []
servers: []
components:
schemas:
CreateTaskDto:
type: object
properties:
title:
type: string
description:
type: string
labels:
type: array
items:
type: string
required:
- title
UpdateTaskDto:
type: object
properties:
title:
type: string
description:
type: string
labels:
type: array
items:
type: string
This specification is basic, without the usage of any authentication mechanism for now. To make it better and future-proof, I propose adding the following functionalities to it:
JWT token authentication
Adding the 'assignee' and 'author' to the schemas
Adding definitions and schemas for the other modules/components.
Let's take a look at the additional endpoints we need:
Users Module:
POST /register
POST /login
POST /logout
POST/PATCH /profile
GET /profile/{user-objectId}
GET /profile
Boards Module:
POST/PATCH /boards
GET /boards/{boards-id}
GET /boards
TasksList Module:
POST/PATCH /tasks-list
GET /tasks-list/{tasks-list-id}
GET /tasks-list
For each of these module endpoints, we already have schemas. They are partially defined based on the database collection definitions. I'll leave it to you to define these in the OpenAPI specification as an exercise.
For error handling, I propose the following HTTP status codes:
400 - Bad Request
401 - Not Authorized
403 - Forbidden (not implemented at the moment; requires permissions to be implemented)
409 - Conflict
For API authentication, we will use JWT tokens. While JWT tokens will serve for authorization in the MVP, we will explore the authorization part and who will take care of it after completing the MVP.
As progress with the MVP development, I will post on each stage the current open API specification yaml file.
I would like to mention again, that the tool used for creating the diagrams is called plantUML. You can find more about this in the first article of the series or on Google. Don't be afraid to google it yourself.

